In either case, it is not the structure per se of the database which provides referential integrity. That is, we cannot ascertain what rules and methods of referential integrity are in force by inspecting only the tables themselves. We must also examine the named constraints, and their internal behaviors, or the procedural code executed in triggers. Thus we have already fragmented our system's rules into three separate complex webs: columns aggregated into tables, not null modifiers, and referential integrity behaviors.
Entity-Relationship models attempt to present the design of an RDBMS instance in a filtered, abstract way.
By hiding the physical details of storage and navigation, the ER model focuses attention on the meaning of data structures - the business rules which they embody.
Of course all the terms must chamge again, not so much to add clarity as to sell more methodology text books. What was first a relation and then a table is now called an entity. The relational attribute, which became an RDBMS column, is now called an attribute again or perhaps it's a data item or data element.
levels of abstraction - normalization - 1NF vs 5NF
Dependent key is not aggregation
Cardinality in Entity-Relationship Diagrams
As stated above, a foreign key can reference only one row in the other, "foreign", table but that same foreign key value set may repeat in any number of rows of the child table. Thus every foreign key reference is one-to-many. Yet almost all Entity-Relationship Diagram (ERD) methods and tools allow us to record one-to-one, one-to-many, and many-to-many. In fact some even capture specific, numeric minimum and maximum cardinality.
Can a relation database digest all of this? No! Every relational FK-PK reference is inherently one-to-zero-or-more. All other forms require specific, non-relational, solutions. Some examples:
One-to-one is a commonly allowed form. Yet clearly the existence of a foreign key column set in no way limits the occurrence of a foreign key value to only one row. It can be done by several methods . This list is not offered as complete nor is it ordered with meaning:
One-to-many relationships in ERDs are by far the most common. These do not cause problems unless they carry specific cardinality constraints on the child; e.g., "1,1 team : 1,5 team member". It is important to know that each team has at least one and no more than five members. But these values cannot be imposed by the structure of the database. They require on of:
Many-to-many relationships are well understood by all database designers and most CASE tools. They must cause the creation of an intermediate associative table to resolve the multiple references. This is no problem if your CASE tool either does it or tells you it can't do it. Or you can avoid many-to-many relationships is an ERD by explicitly modeling the associative entities. The latter path has pros and cons but it certainly sidesteps failings of a CASE tool in this regard.
Sub-type / super-type structures pose special problems:
One-to-one relationships between sub-types and its super-types are generally enforced with an inherited primary key ("dependent" in S-Designor and Silverrun, "identifying" in ERwin, ER/1, and System Architect). This method is effective but weak because it presumes the designer will never assign a different primary key in the sub-type. A more appropriate solution would be to force a unique index or alternate key on the super-type foreign key.
Complete sub-type sets are a default property in some CASE tools (Oracle CASE and most SSADM tools) and optional in others such as ERwin, ER/1, and S-Designor. A complete subtype set is logically equivalent to a minimum sub-type cardinality of one. This situation should create or suggest some means to enforce the existence of one sub-type row for each super-type row. Unfortunately, we know of no CASE tool which even suggests that the user should solve this problem, let alone offers to generate code for it.
Incomplete sub-type sets do not require at least one sub-type per super-type row so no enforcement is needed.
Exclusive sub-type sets are a default property on come CASE tools such as ERwin and ER/1 and optional in others such as S-Designor. Exclusivity implies some check before insert or update of a sub-type. This could be a trigger based check; a code check of a "category discriminator" attribute, a la IDEF1X; or some other application code external to the database.
In a nutshell, a relational database can deal directly only with the cardinality 0,1 : 1,N. When we model any other cardinality form we (or our CASE tool) must create non-structural solutions.
mutually mandatory
optional parent
OR connector in SA; arc
Attribute Roles
So far we have seen how data modeling methods and tools draw us insidiously into a trap of representing some things which are solved and some which are left undone. So our model represents not the database but rather our use of the database. Or does it? Can any data modeling tool or method capture all the constraints we need to express?
Our company is small and we have only a few employees. We work and live in an area where people cherish their convenience and free time. Although many of our employees live within walking or bicycling distance, and in spite of our blandishments about exercise and the environment, only a few choose not to drive. So parking spaces are a valued benefit to our commuters
But there are some among us who do walk, bike, or even row to the office every day. They, understandably, felt left out of the goodies when we assigned parking places to those who drive regularly.
Wanting to be fair to all, we calculated our cost per parking space for the company garage and offered each employee a choice: take an assigned parking space or receive the cash as a commuting allowance The drivers are happy; they don't have to give up their parking to accommodate the health nuts and environmentalists. The non-drivers like this too; one even saved enough to buy a new rowing shell. Internally, however, we have a systems problem: how do we model this in an entity-based model?
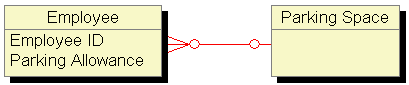 Each employee is assigned either a parking space (say "A19") or a
commuting allowance (e.g., $35). In an ERD we draw relationships only between entities
- not between attributes. Clearly "parking space" is an entity. Each
space exists with or without an employee assigned to it and the company pays a garage
rental based on the number and location of spaces.
Each employee is assigned either a parking space (say "A19") or a
commuting allowance (e.g., $35). In an ERD we draw relationships only between entities
- not between attributes. Clearly "parking space" is an entity. Each
space exists with or without an employee assigned to it and the company pays a garage
rental based on the number and location of spaces.
But just as clearly "commuting allowance" is merely an attribute - a value without any existence or meaning on its own. The answer is: we don't. Entity-Relationship modeling does not capture all the constraints we must recognize for useful systems solutions. So now we know:
State Transitions
The above scenario is a lot simpler than almost any real life situation. What are the rules, for example, about when an employee can be assigned a parking space? Can a parking space be reassigned? What about changing the commuting allowance?
Our data model can only represent the least constrained potential for this database design. We have no way to represent or even capture intermediate conditions and their enabling or causative factors.
For example, an employee is assigned a commuting allowance 60 days after hire (should he last so long). But parking spaces are only assigned every six months. So clearly some employees have neither, some are eligible only for an allowance, and some may be ready to receive a parking space assignment.
Some CASE tools throw in a few fragments of state transition. For example, S-Designor has its "Change parent allowed" check box to deal with one minor aspect of value change. This is worse than no feature at all because it seems to imply greater significance to that one value change control than to any others, which are not even discussed.
On the other hand, classic large CASE tools, and a few smaller ones like System Architect, attempt to provide a complete state transition mechanism outside of the data modeling environment.
In Summary
We have seen how many of the features and techniques of conventional data modeling are not about database design but rather about the number, range, and change of values through time. These constraints cannot be designed into a relational schema per se. They typically require some additional code solution.
This causes two problems:
We propose that any CASE tool or method capable of modeling constraints beyond relational database structure should identify and report all such constraints so that the user can make appropriate partitioning decisions and provide code where the CASE tool cannot.
Where to go from here:
©
© 1996 Applied Information Science International