30 Oct 1996 updated
This is a working document where I’m doodling my thoughts. Don’t expect it to make sense, let alone be complete.
This paper is written to explore the differences and confusions between relational database structure and the various ways in which we attach or execute behaviors to implement business rules over databases.
Over the last ten years relational database vendors have engaged in constant feature wars, vying for first place honors on the product checklist. Certainly we find constructive use for all these features from time to time in various designs and configurations. Our options for the storage and maintenance of data have become much more extensive from the vendors competition.
Yet we should not assume that, because a particular feature exists, that feature is the best, or even appropriate, approach for a particular need. For example, When Sybase acquired a reputation for technical leadership based on its innovative stored procedures, Sybase worked very hard to persuade us that all non-interface code belonged bound into their database. This was never true - not then and not now. The existence of the stored procedure feature did not ipso facto mean that was a better way to code.
In fact, as we discuss below, intelligent design of database systems will involve several different layers and methods for optimal construction, performance, security, and life-time cost.
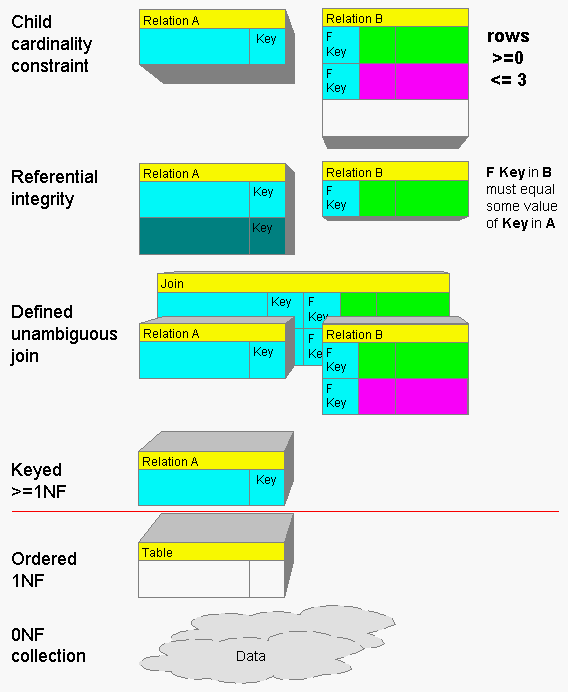
In the diagram above, every concept above the red line is non-structural,
i.e., does not have any effect on the structure of relational tables. This
includes joins predefined by declared foreign keys ("relationships"),
foreign key cardinality constraints, and referential integrity rules. All
of these concepts can be implemented with either DBMS extensions or procedural
code executed anywhere in an n-tier scheme.
For example, one could use the DECLARE PRIMARY KEY statement to implement a primary key constraint. However, since a primary key constraint is really nothing but enforced uniqueness, one could do the same with a unique index or a trigger to select on the specified column(s) to test for pre-existing values.
Page 1-12 of the Sybase SQL Server Reference Manual (System 10) says, regarding the declarative primary key constraint: "constrains the values in the indicated column or columns so that no two rows can have the same value, and so that the value cannot be NULL. This constraint creates a unique index that can only be dropped if the constraint is dropped."
Page 386 of Oracle 7 - the Complete Reference by George Koch defines candidate keys and primary keys, making clear that either can be declared to enforce uniqueness
The same test could be performed through client code in any programming language with access to the table. Similarly, one could implement insert referential integrity with an ALTER TABLE declaration of the intended foreign key - primary key pairing. In this case, every database with which I am familiar requires the specification of the precise column(s) in both "foreign key" and "primary key" tables.
Page 1-13 of the Sybase SQL Server Reference Manual (System 10) says, regarding the declarative alter table references constraint: "specifices a column list for referential integrity constraint" for both foreign key and referenced tables.
Page 387 of Oracle 7 - the Complete Reference by George Koch discusses foreign keys and referential integrity. As in Sybase, Oracle allows the complete specification of column sets in both the child ("foreign key") and parent tables.
Or one could perform a pre-insert select, via trigger, stored procedure, or client code, to test for existence of the primary key value. Any of these methods work equally well, aside from performance in a particular configuration.
Thus we can deduce two principles:
1. All behaviors attached to data are just that: behaviors, not structures. They should be modeled and constructed as such using the same object mechanisms employed for any other system behaviors.
2. Specifying behaviors in a data model for implementation via database extensions means accepting implicit partitioning onto the server side. Such application partitioning should be a deliberate, planned architecture reflected in system models and documentation, rather than being buried in implicit utilization of DBMS vendors’ features.
We first adopted the acronym READ (Read, Edit, Append, Delete) more than ten years ago to remind ourselves of the hierarchy of data access in dBase II (and, subsequently, its derivatives as well). We crafted user security and data manipulation routines based on a class structure of inherited behaviors.
Today, adapting to the universal data language of SQL, we think in terms of SQUID: Select query, Update, Insert, Delete. Either acronym suggests four separate data access entry points, or four object levels providing different scope of methods operating on data.
Delete is the most carefully restricted level since this action must, at least, take into account referential integrity of existing foreign key values.
Insert generally must perform numerous checks for inter-table, inter-row, intra-domain, and column-specific constraints.
Update by definition operates only on the columns specified in the update request. Therefore its duties are generally less numerous and demanding than Delete or Insert.
Select needs only the service of valid retrieval, interpretation, and presentation. Obviously this action cannot change any values in the database so its methods are the least restrictive.
One way in which this concept has sometimes been implemented in relational databases is through the selective use of stored procedures which attach to the database as fictitious users. If the database grants only Select to real users, they will have no way to escape the planned access points for more restrictive operations. Rights to perform Update, Insert, and Delete are granted to fictitious system users which attach to the database only within the context of stored procedures written to execute those operations.
These stored procedures are then called from application code whenever there is a need to perform any level of data access. The application code acts to merely invoke the stored procedure, which contains pre-tested, optimized, and compiled code to perform the appropriate data access. T
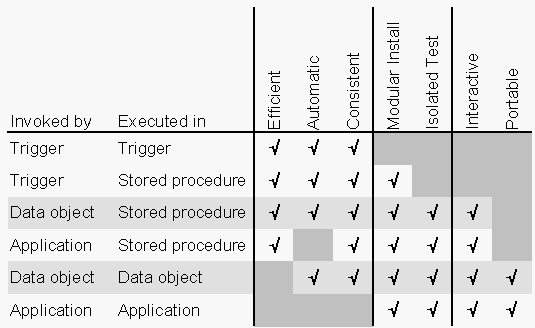
he table below summarizes several approaches to packaging data access and control logic, contrasting their strengths and weaknesses